
Imagine que, de repente, o sistema da sua empresa começa a ficar lento. Os usuários reclamam, o suporte abre chamados e o time de engenharia corre para descobrir o motivo.
Os dashboards mostram que há erros e picos de CPU, mas ninguém sabe onde está o gargalo.
- É o banco de dados?
- Uma API externa?
- Um loop infinito em algum serviço?
Agora imagine outro cenário:
O produto está estável, mas as vendas caíram 20% em uma semana. Não há incidentes aparentes, tudo parece “verde” nos painéis, mas algo no fluxo do usuário quebrou.
O time de negócio pressiona, o marketing suspeita de uma campanha e o time técnico percebe que… faltam dados para entender o que realmente aconteceu.
Essas situações são comuns em empresas de todos os tamanhos e têm algo em comum: a falta de observabilidade.
O que é observabilidade?
Observabilidade é a capacidade de entender o que acontece dentro de um sistema, mesmo sem enxergar diretamente seu funcionamento interno.
💡 Pense em um sistema como uma caixa preta: você não vê o que ocorre lá dentro, mas consegue deduzir seu estado analisando os dados de entrada, saída e comportamento.
Em outras palavras, é sobre conseguir fazer novas perguntas sobre o sistema — e encontrar respostas com os dados disponíveis, sem precisar adicionar logs ou métricas toda vez que algo foge do esperado.
Por que a observabilidade é importante?
- Permite detectar e diagnosticar problemas rapidamente.
- Dá contexto para decisões técnicas e de negócio.
- Facilita o entendimento de sistemas distribuídos e integrações complexas.
- Ajuda a antecipar falhas antes que impactem a experiência do usuário.
Mais do que reagir a incidentes, observabilidade é sobre entender o comportamento real do sistema e empoderar times a tomarem decisões baseadas em evidências.
Observabilidade vs. Monitoramento: a diferença essencial
O que é monitoramento?
- Avisa quando algo sai do esperado (ex: latência acima do normal).
- Depende de métricas e regras pré-definidas.
- Mostra sintomas, mas raramente as causas.
O que é observabilidade?
- Permite investigar causas-raiz.
- Dá liberdade para explorar dados e formular novas perguntas sem precisar prever todos os cenários.
- Conecta métricas, logs e traces, permitindo enxergar o sistema como um organismo único.
De forma pratica e objetiva:
- Monitoramento mostra o que está errado, ou seja acende o alerta.
- Observabilidade explica por que está errado, ou seja explica o motivo, o impacto e o caminho para a solução.
Os três pilares da observabilidade
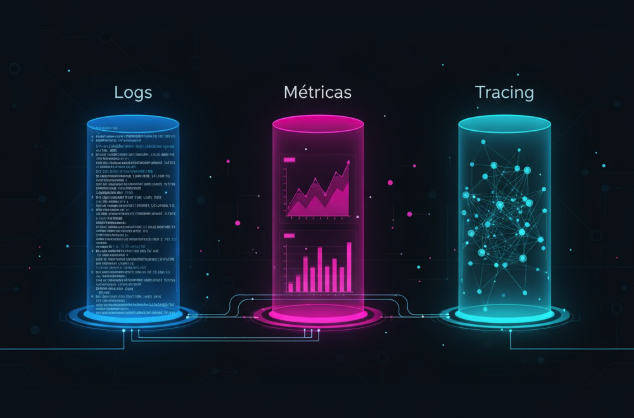
A observabilidade se apoia em três tipos de dados de telemetria. Quando correlacionados, eles revelam o estado interno do sistema e contam sua história com clareza:
- Métricas: dados numéricos agregados ao longo do tempo (ex: uso de CPU, latência, contagem de erros). Servem para identificar tendências e acionar alertas.
- Logs: registros detalhados de eventos (ex: uma transação concluída, um erro em uma API). Mostram o contexto no exato momento em que algo ocorreu.
- Traces (rastreios distribuídos): representam o caminho completo de uma requisição entre serviços. Permitem descobrir onde exatamente está o gargalo em um sistema distribuído.
Exemplo prático:
Ao investigar um erro de checkout, as métricas mostram aumento de falhas, os logs revelam que a API de pagamento retornou erro, e os traces indicam qual microserviço causou a lentidão.
É a combinação desses três tipos de dado que permite entender, de fato, o que aconteceu.
Como aplicar observabilidade no dia a dia da engenharia
A observabilidade não começa na produção, ela nasce ainda no refinamento técnico e acompanha todo o ciclo de desenvolvimento.
Pensar em observabilidade desde o design evita depender apenas de alertas quando algo já deu errado.
Aqui estão algumas práticas universais para tornar seu sistema realmente observável:
- Defina métricas que importam. Combine indicadores técnicos (latência, erros, throughput) com indicadores de negócio (taxa de sucesso, conversão, engajamento).
- Crie dashboards que contem histórias. Bons gráficos mostram mais que números — mostram contexto e impacto.
- Configure alertas inteligentes. Evite alertas genéricos e priorize os que refletem impacto real.
- Implemente rastreabilidade. Tenha logs estruturados, auditoria de dados e correlação entre eventos.
- Relacione observabilidade à experiência do cliente. Nem toda falha técnica causa impacto direto — e nem todo sistema “verde” garante uma boa experiência.
Ferramentas vs. cultura: a mentalidade observável
Ferramentas ajudam, mas observabilidade é mais cultura do que stack.
Não importa se sua equipe usa Datadog, Grafana, Prometheus, Honeycomb, OpenTelemetry ou ELK, o que faz diferença é o hábito de observar, aprender e ajustar continuamente.
Equipes maduras entendem que cada incidente é uma oportunidade de aprendizado.
Não se trata de “quem errou”, mas de o que o sistema nos ensinou.
Conclusão
Observabilidade não é apenas sobre gráficos e alertas.
É sobre entender o invisível, os sinais sutis que contam a história do sistema.
Quando times adotam a observabilidade como prática e cultura, deixam de apagar incêndios e passam a construir sistemas mais saudáveis, previsíveis e humanos.
Times que investem em observabilidade deixam de reagir a falhas e passam a antecipar o futuro do sistema.